An elderly Medicare patient needs post-acute rehabilitation care. Their doctor says so. The hospital says so. UnitedHealthcare’s AI model disagrees.
A class action lawsuit filed in November 2023 alleged that UnitedHealth’s algorithm, called nH Predict, was denying rehabilitation coverage to seriously ill patients at scale, including cases involving feeding tubes and severe pressure wounds. The lawsuit alleged that nine out of ten of those denials were overturned on appeal. A U.S. Senate Permanent Subcommittee on Investigations report, published in October 2024, found that UnitedHealthcare’s prior authorization denial rate for post-acute care jumped from 10.9 percent in 2020 to 22.7 percent in 2022, as the company was implementing automated review processes. The lawsuit further alleged UnitedHealth knew about the error rate and kept using the model anyway, because only 0.2 percent of denied patients actually appeal.
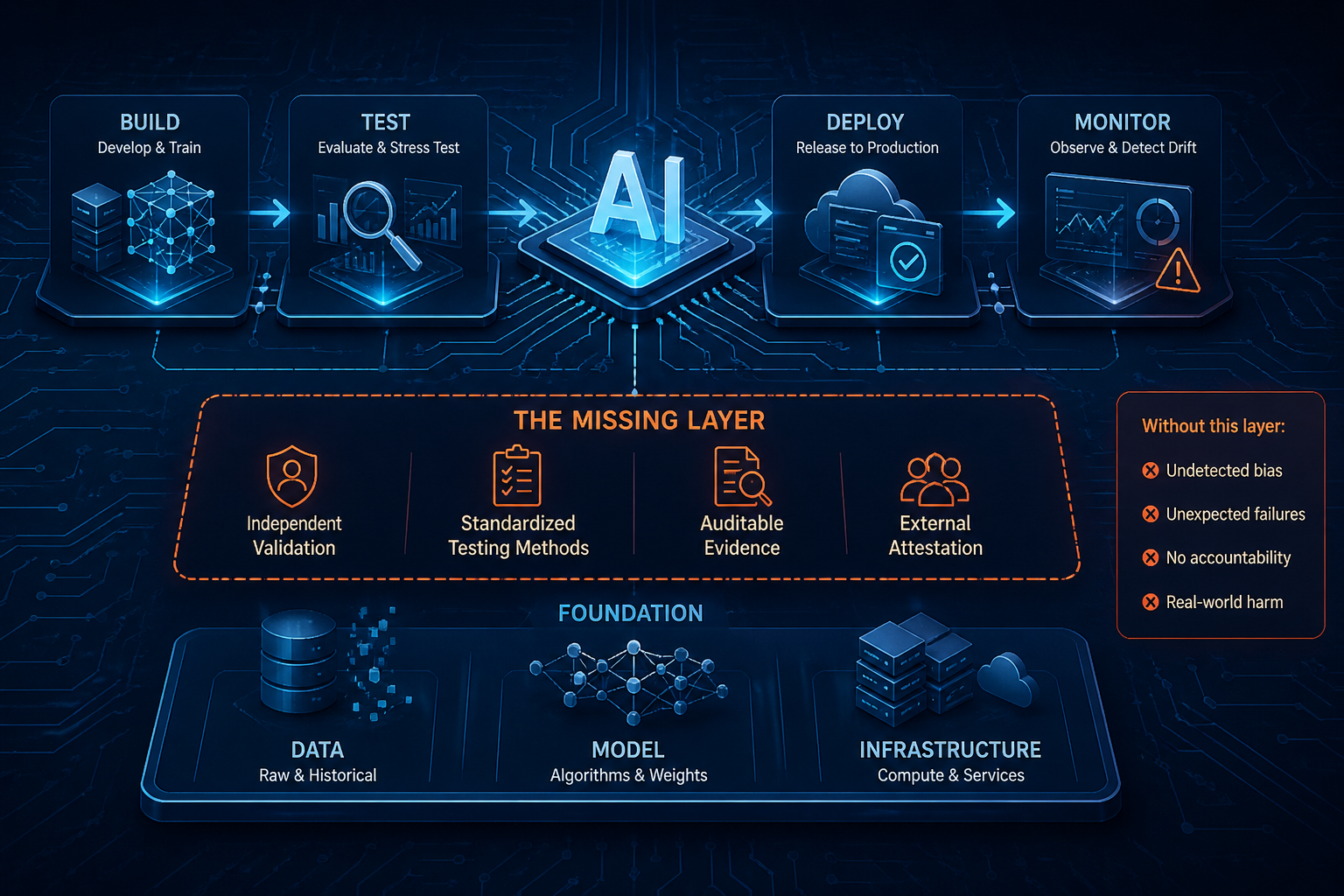
The model wasn’t secret. The company had engineers. They almost certainly had some version of a review process. What they did not have was a requirement to prove the system worked before it touched a real patient. No independent audit. No outcome validation against clinical ground truth. No standard that said: here is what you must demonstrate before this model overrides a physician.
This is not a story about a company that didn’t care about responsible AI. It is a story about what happens when internal processes, however serious, are not the same thing as auditable governance.
You probably already do some of this
If you work on AI systems at a serious technology company, you have likely built some version of the following: model cards documenting training data and intended use, red teaming exercises to find unexpected failure modes, bias evaluations across demographic groups, human review gates before deployment, post-launch monitoring dashboards.
Meta’s responsible AI work on Llama 3, for example, included extensive red teaming with internal and external experts, benchmark testing against CyberSecEval, and safety fine-tuning using reinforcement learning with human feedback. That is real work done by serious people.
So why isn’t it enough?
Because none of it is independently verifiable by someone outside the organization. Because there is no agreed methodology for what “bias evaluation” means, which benchmarks to run, what thresholds constitute passing, or what happens when a model drifts after launch. Because the person who signs off on deployment and the person who built the system are often the same team, or at least the same company. And because when something goes wrong, there is no independent record of what was tested, what was found, and what decision was made anyway.
Internal review is necessary. It is not sufficient. The difference between the two is the same difference that exists in financial auditing, clinical drug trials, and aviation safety. Companies can have excellent internal processes and still require external attestation. That requirement is not an insult to the internal work. It is what makes the internal work credible to everyone outside the building.
The pattern shows up everywhere
Amazon built an AI hiring tool starting in 2014, trained on ten years of historical resumes. Because most applicants had historically been men, the model learned to prefer male candidates. It downgraded resumes that included the word “women’s.” It ranked candidates higher for verbs that appeared more often on male resumes. By 2017 the company had scrapped it.
There was pre-deployment testing. What was missing was an independent requirement to test specifically for demographic disparities before the system touched real candidates, and a standard that defined what passing that test looks like.
In 2022, Jake Moffatt flew from Vancouver to Toronto after his grandmother died, relying on Air Canada’s chatbot, which told him he could apply for a bereavement discount retroactively within 90 days. He screenshotted the conversation. The airline denied his claim. In court, Air Canada’s lawyers argued the chatbot was a “separate legal entity responsible for its own actions.” A British Columbia tribunal rejected that and ordered the airline to pay $812 Canadian in damages. The chatbot disappeared from the website shortly after.
An AI engineer reading that case immediately understands what happened: a retrieval system and a static policy page were out of sync, and nobody was required to test for that sync before deployment. That is a data pipeline problem. The governance failure is that no standard required it to be caught.
Three industries. Three types of AI. The same failure in all of them: no one was required to prove the system worked before it reached a real person. Not to themselves. Not to anyone outside the building.
What already exists, and where it breaks down
NIST released its AI Risk Management Framework in 2023, extended it with a generative AI profile in 2024. ISO 42001 provides a certifiable management system standard with third-party auditors. The EU AI Act creates legally binding obligations with fines reaching up to 40 million euros or 7 percent of global revenue.
These are serious efforts. But none of them is yet a finished, auditable standard with agreed testing methodologies, trained auditors, and certifications the market actually recognizes.
NIST is voluntary, with no auditor community behind it. ISO 42001 covers governance process well, but analysis from compliance and legal researchers, including GLACIS and ISMS.online, indicates it addresses only a portion of what the EU AI Act requires for high-risk systems, leaving gaps in mandatory incident reporting, public registries, and conformity assessments that hold up in court. The EU AI Act has enforcement teeth but the auditor infrastructure is still being built.
So we have principles without testable controls. Frameworks without trained auditors. Regulations without enforcement infrastructure. And AI systems running right now that affect people’s healthcare, employment, and finances.
The people best positioned to write these controls are not primarily in Brussels or Gaithersburg. They are in GRC teams, risk functions, and, critically, in engineering organizations that already know where the hard problems live.
What the standard actually needs to say
Here is where the conversation gets harder. Because “we need a standard” is easy. What the standard should actually require is where engineers and GRC people need to be in the same room.
Risk tiering that accounts for how AI systems are actually built
Every AI governance framework talks about risk tiers. Most of them imagine a clean mapping between one AI system and one risk level. That is not how large-scale AI deployment works.
At a company deploying AI at scale, one foundation model might power dozens of product surfaces with very different risk profiles. A content recommendation model and a credit decisioning model can share underlying architecture. The standard needs to tier risk at two levels: the model layer and the application layer, separately. The foundation model provider carries responsibility for what the base model does. The deployer carries responsibility for how it is applied. Right now, that split is unresolved in almost every major framework, including the EU AI Act, where the distinction between provider and deployer is still being interpreted in practice.
This is not a theoretical problem. It has direct implications for who signs the attestation, who gets audited, and who is liable when something fails in a deployed application built on a third-party model.
Pre-deployment testing with defined methodology, not just defined intent
“Documented bias testing across protected classes” sounds clear until someone asks: which benchmarks, what sample sizes, what threshold constitutes passing, and who decides.
Right now, each company answers those questions internally. That means “we ran bias testing” can mean rigorous demographic parity analysis across millions of samples, or it can mean a two-hour manual review before a product launch. Both satisfy the same self-reported requirement.
The standard needs to define the methodology, not just the obligation. For high-risk systems, that means specified evaluation suites, required sample sizes tied to deployment scale, defined pass/fail thresholds, and a sign-off process not owned entirely by the team that built the system. Amazon’s hiring tool likely had some internal review. What it lacked was a required methodology that an external auditor could test against.
UnitedHealth’s claims model would have looked very different if an independent party had been required to validate its error rate against clinical outcomes before it touched a single patient.
Continuous monitoring with defined triggers, not just launch-time checks
AI engineers know this problem better than anyone: models drift. The world changes and the training distribution does not. A model that tested well at launch can behave differently six months later because the input distribution shifted, not because anything changed in the model itself.
The standard needs to require continuous monitoring with defined review triggers and documented escalation paths. Not annual reviews. Not “we check the dashboard when something looks wrong.” Specific metrics, specific thresholds, specific timelines for response. The UnitedHealth denial rate doubled over two years. A monitoring standard with defined triggers would have forced a review long before it reached the numbers the Senate investigation documented.
The foundation model problem nobody wants to own
This is the hardest part, and most frameworks currently walk past it.
If your AI system is built on a foundation model your company did not train and cannot fully inspect, the standard governance questions become genuinely hard to answer. Who is responsible for the base model’s bias profile? Who attests to its safety characteristics? If the foundation model provider updates the model and the deployment behavior changes, who is responsible for the change and what testing is required before it reaches production?
The EU AI Act attempts to distinguish between providers and deployers, but legal researchers studying it note that the line becomes particularly difficult when fine-tuning is involved. If fine-tuning doesn’t materially change risk, the foundation model provider may retain responsibility. If it does, the deployer may become the de facto provider with full compliance obligations. That determination has to be made on a case-by-case basis, under a framework that doesn’t yet have enough case law to be predictable.
A real standard has to assign that responsibility explicitly, with defined criteria for when it transfers. Companies building on Llama, or GPT, or Gemini need to know who signs the attestation and under what conditions. Right now the answer is effectively nobody, because the question hasn’t been forced.
Independent attestation backed by a trained auditor community
Everything above is only as good as the people checking it.
There is no widely recognized training path for an AI auditor today. No agreed evidence standard. No certification body between the company and the public. Internal red teams are essential. They are also not independent. The difference is not a judgment on internal teams. It is a structural requirement.
The compliance automation tools will come once the standard exists. Evidence collection will get automated. Monitoring will get continuous. Certification will get faster. That is exactly what happened when cloud security compliance matured and tooling built on top of it. Automation follows definition. It cannot come first.
Self-certification for high-risk AI is not accountability. It is paperwork with good branding.
The window is open right now
The frameworks have told us what AI governance should look like. Nobody has done the harder work: defined the controls with enough specificity that an auditor can test them, mapped the evidence requirements for systems built on foundation models, trained the auditors, and built the attestation infrastructure that makes any of it real under examination.
That work requires both GRC practitioners and AI engineers in the same room. GRC people know what auditable means in practice. Engineers know where the controls actually have to live in the system. Neither group can write this standard without the other.
The window to shape this before it gets shaped for us is open. Not indefinitely.
If you are working on AI governance from the engineering side or the compliance side, I want to hear what you are seeing. Where are the gaps your current framework cannot resolve? What controls have you tried to build that don’t have a home in any existing standard? The people who show up to answer those questions are the ones who will determine what this standard actually looks like.
Sources
-
UnitedHealth / nH Predict class action lawsuit, November 2023. CBS News. cbsnews.com
-
U.S. Senate Permanent Subcommittee on Investigations, “Refusal of Recovery: How Medicare Advantage Insurers Have Denied Patients Access to Post-Acute Care,” October 17, 2024. hsgac.senate.gov (PDF)
-
STAT News, “Denied by AI: How Medicare Advantage Plans Use Algorithms to Cut Off Care for Seniors in Need,” Casey Ross and Bob Herman, March 2023. statnews.com
-
Meta, “Our Responsible Approach to Meta AI and Meta Llama 3,” April 2024. ai.meta.com
-
Reuters / Jeffrey Dastin, “Amazon Scraps Secret AI Recruiting Tool That Showed Bias Against Women,” October 2018. Via MIT Technology Review. technologyreview.com
-
Moffatt v. Air Canada, 2024 BCCRT 149, British Columbia Civil Resolution Tribunal, February 14, 2024. cbc.ca
-
NIST AI Risk Management Framework 1.0 (2023) and Generative AI Profile NIST AI 600-1 (2024). nist.gov
-
ISO 42001 vs. EU AI Act gap analysis. GLACIS and ISMS.online. glacis.io · isms.online
-
EU AI Act provider vs. deployer distinction, foundation model governance. Oxford Law Blogs. blogs.law.ox.ac.uk
-
EU AI Act fine structure. ModelOp. modelop.com